Gebruik#
Instellingen#
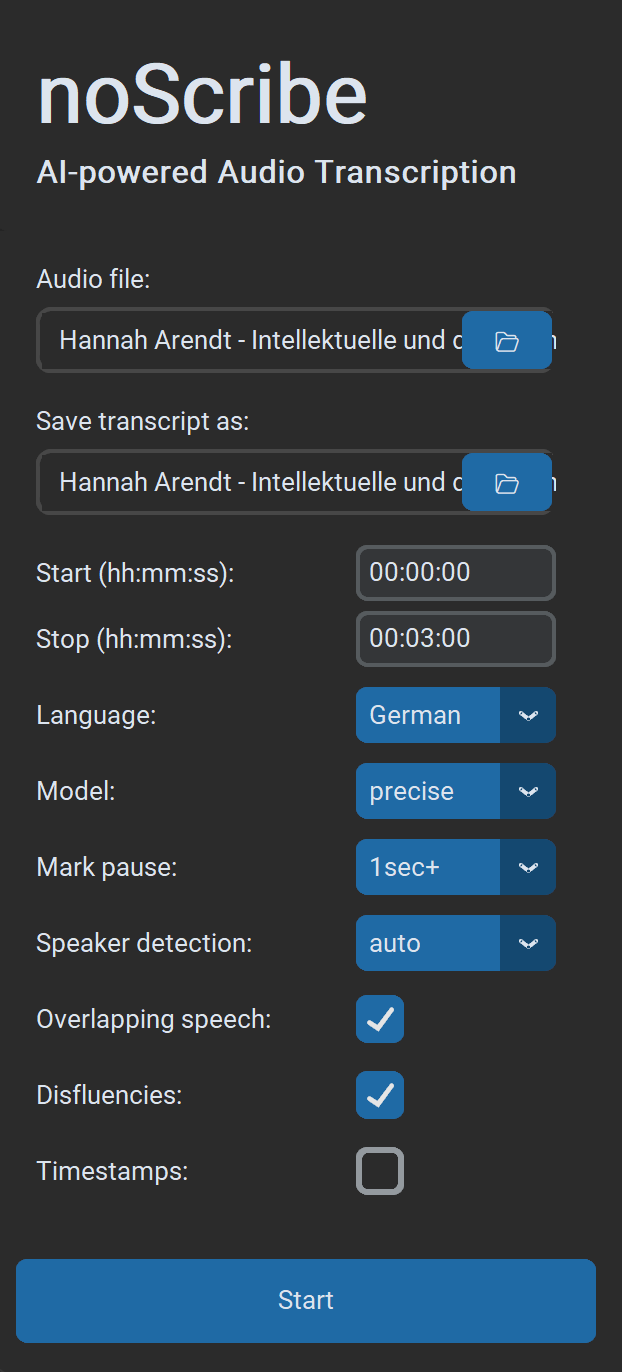
- Audiobestand: Bijna alle audio- en videoformaten worden ondersteund. Je kunt ook meerdere bestanden selecteren; ze worden dan achter elkaar verwerkt.
- Transcript opslaan als: Standaard is dit
.html(compatibel met de editor). Optioneel.txtvoor platte tekst of.vttvoor ondertitels en verdere verwerking in EXMARaLDA. Als meerdere invoerbestanden tegelijk worden verwerkt, kan alleen de uitvoermap worden gekozen. Bestandsnamen worden dan automatisch gegenereerd. - Start/Stop: Tijdsbereik in het formaat
hh:mm:ss, ideaal om kortere fragmenten te testen. - Taal: Kies een taal of “Auto” voor detectie, of “Multilingual” voor meerdere talen in dezelfde opname (experimenteel).
- Model: “Precise” levert de beste resultaten en is de aanbevolen keuze voor vrijwel alle toepassingen. “Fast” is iets sneller en vooral bedoeld voor oudere computers. Het vraagt meer nacorrectie.
- Pauzes markeren: Indien geselecteerd, worden pauzes gemarkeerd met punten tussen haakjes, een punt per seconde pauze. Optioneel vanaf 1/2/3 seconden.
- Sprekerdetectie: Als het aantal sprekers bekend is, selecteer dit om de detectie robuuster te maken. Kies anders “Auto” voor automatische detectie of “None” om deze stap helemaal over te slaan.
- Overlappende spraak: Gelijktijdige spraak wordt gemarkeerd met
// Speaker: tekst van de interjectie //(experimenteel). - Disfluencies: Indien geselecteerd, worden stopwoorden en onvolledige woorden/zinnen waar mogelijk getranscribeerd; anders niet. Opmerking: dit is meer een “aanbeveling” aan het AI-model, geen harde aan/uit-schakelaar.
- Timestamps: Plaatst een timestamp in het formaat
[hh:mm:ss]elke 60 seconden of bij wisseling van spreker (bijv. handig voor MAXQDA). - Start start het transcriptieproces. Als er al een proces loopt, kun je toch nieuwe taken toevoegen. Die komen dan in de wachtrij en worden verwerkt wanneer ze aan de beurt zijn.
Wachtrij#
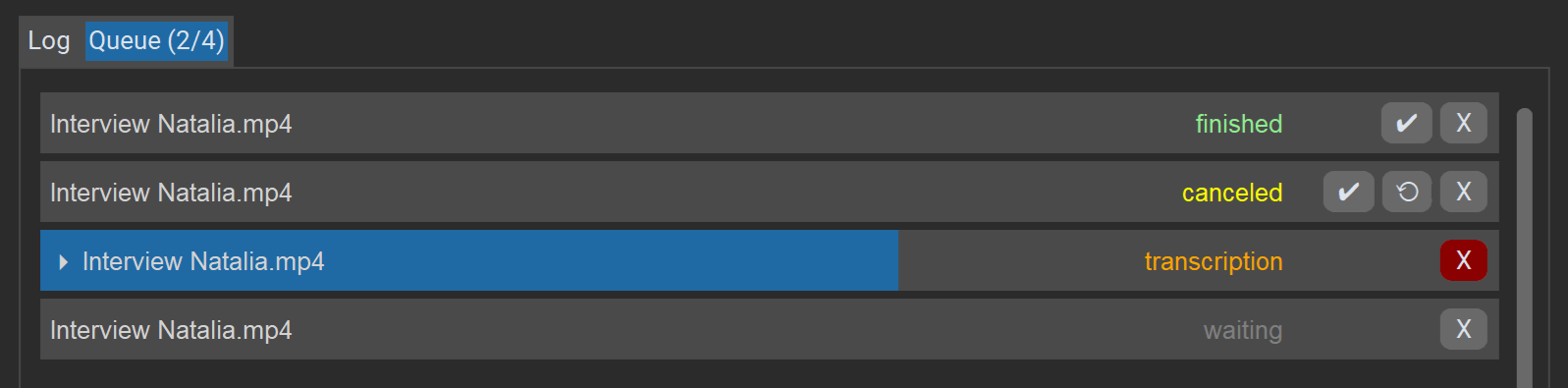
Het tabblad “Queue” toont een lijst van alle taken in de huidige sessie, hun status en voortgang. Taken worden een voor een verwerkt.
Acties voor taken:
Xverwijdert of annuleert een taak.✔opent het resultaat in de editor (ook als er fouten waren, zolang er een onvolledige transcriptie bestaat).⟳start een taak opnieuw (na fouten/annulering).
De knop “Cancel” rechtsonder stopt de hele wachtrij.
De noScribe Editor#
De editor is een belangrijk onderdeel van noScribe. Hij wordt gebruikt om transcripten te controleren en te corrigeren. Zelfs met de beste AI-modellen is dit nog steeds noodzakelijk.
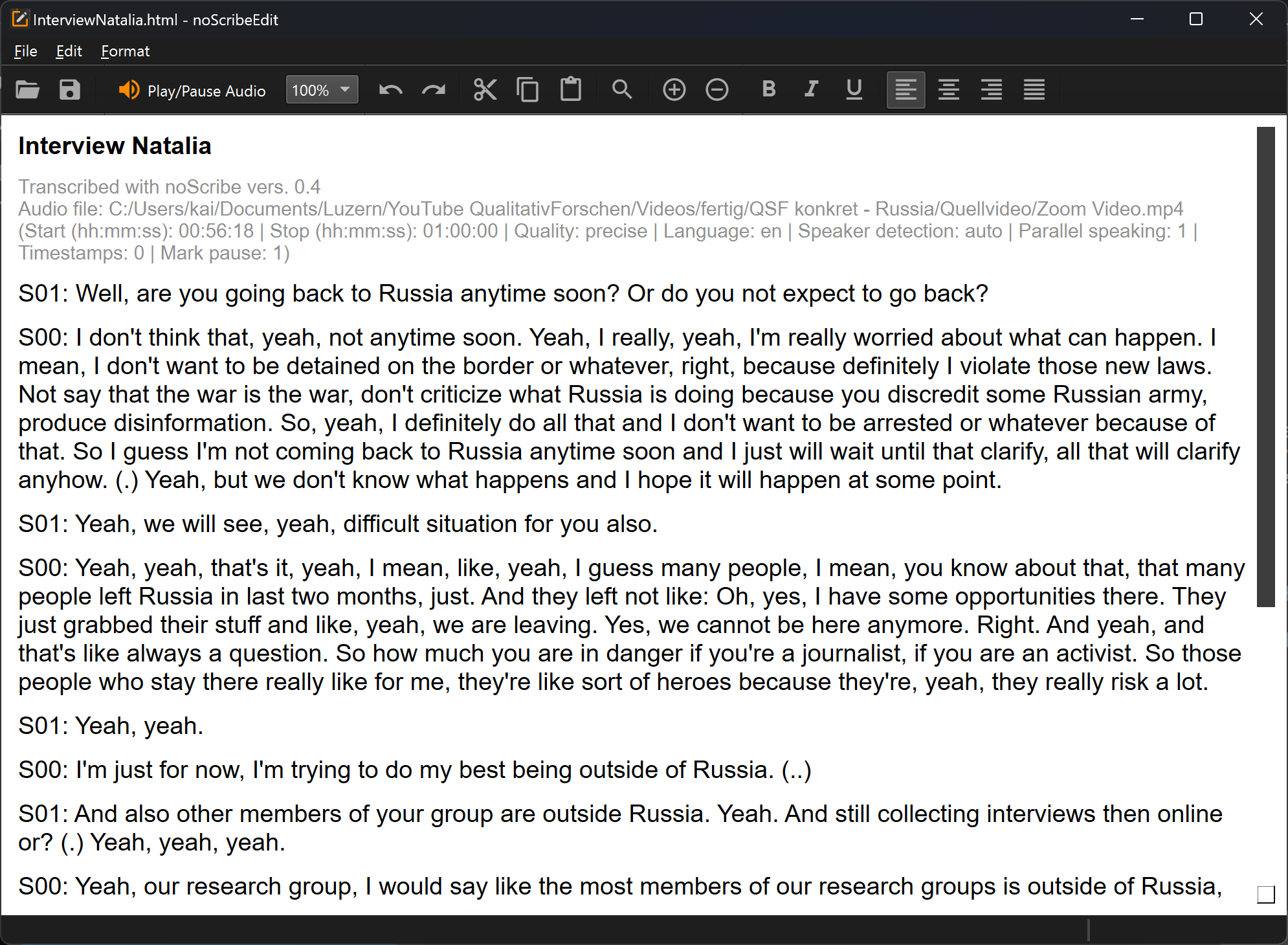
De belangrijkste functie: Ctrl+Spatie (Mac: ^Spatie) of de oranje knop start de audio op de huidige cursorpositie. De tekstselectie volgt de audio. Om te bewerken klik je ergens in de tekst of navigeer je met de pijltjestoetsen.
Andere werkbalkfuncties:
- De keuzelijst (“100%”) laat je de afspeelsnelheid verhogen of verlagen.
- Het vergrootglas opent een zoek/vervang-dialoog. Dit is handig, bijvoorbeeld om sprekersnamen te wijzigen.
- Plus/Min: zoomfunctie
- Er zijn ook typische editorfuncties om bestanden te openen, te kopieren of tekst op te maken. De gebruikelijke sneltoetsen (bijv. Ctrl+C om te kopieren) werken ook. Alle functies zijn ook via de menu’s toegankelijk. Helaas is de editor-UI momenteel niet vertaald.
De noScribe Editor is een zelfstandige app die ook los van het hoofdprogramma kan worden gebruikt.
Broncode: https://github.com/kaixxx/noScribeEditor
Typische problemen bij AI-ondersteunde transcriptie#
AI-gestuurde spraakherkenning heeft de laatste jaren enorme stappen gezet. Toch zijn er typische problemen, fouten en beperkingen om op te letten:
- Niet-verbale uitingen zoals lachen, zuchten, enz. worden niet vastgelegd en moeten handmatig worden toegevoegd.
- Gelijktijdige spraak en zeer dichte interactieve passages, bijvoorbeeld in groepsdiscussies, zijn uitdagend voor het AI-model. Inhoud kan verloren gaan of aan de verkeerde personen worden toegewezen.
- Soms worden meer sprekers gedetecteerd dan er daadwerkelijk waren. In dat geval helpt het om het juiste aantal vooraf in “Sprekerdetectie” in te stellen.
- Ongebruikelijke namen van personen of organisaties, jargon of woorden uit andere talen worden vaak verkeerd gespeld, soms bijna fonetisch. Zoeken en vervangen in de noScribe Editor kan helpen.
- Net als andere taalmodellen kan het Whisper-model hier soms “hallucineren” en woorden of zinnen toevoegen die plausibel klinken maar niet zijn uitgesproken - zie deze studie van Cornell University over het onderwerp.
- Zelden kunnen er oneindig herhalende tekstlussen optreden, vergelijkbaar met een defecte plaat. In dat geval: transcribeer kortere stukken met een lichte overlap en voeg ze handmatig samen.
- Een mix van meerdere talen in dezelfde opname kan ertoe leiden dat het AI-model vertaalt in plaats van letterlijk te transcriberen.
- Bij lange audiobestanden kunnen interpunctie en hoofdletters verloren gaan. In dat geval kan het helpen om de transcriptie te splitsen, of je kunt het transcriptiemodel “faster-whisper-large-v2” gebruiken, dat minder gevoelig is voor dit probleem. Dit moet echter eerst worden geinstalleerd.
- De kwaliteit van het resultaat hangt sterk af van de taal. Westerse talen worden doorgaans zeer goed ondersteund, inclusief kleinere talen zoals Nederlands. De ondersteuning is ook goed voor Koreaans, Chinees (Mandarijn) of Indonesisch. Daartegenover worden andere grote talen zoals Perzisch, Punjabi of Tamil veel minder nauwkeurig getranscribeerd. Dit is een duidelijk geval van AI-bias, die de economische belangen van OpenAI weerspiegelt, die het Whisper-model heeft getraind. Hier is een overzicht van typische foutpercentages in verschillende talen. Zie ook dit artikel voor een vergelijking van verschillende transcriptiemodellen en hun foutpercentages.