Uso#
Impostazioni#
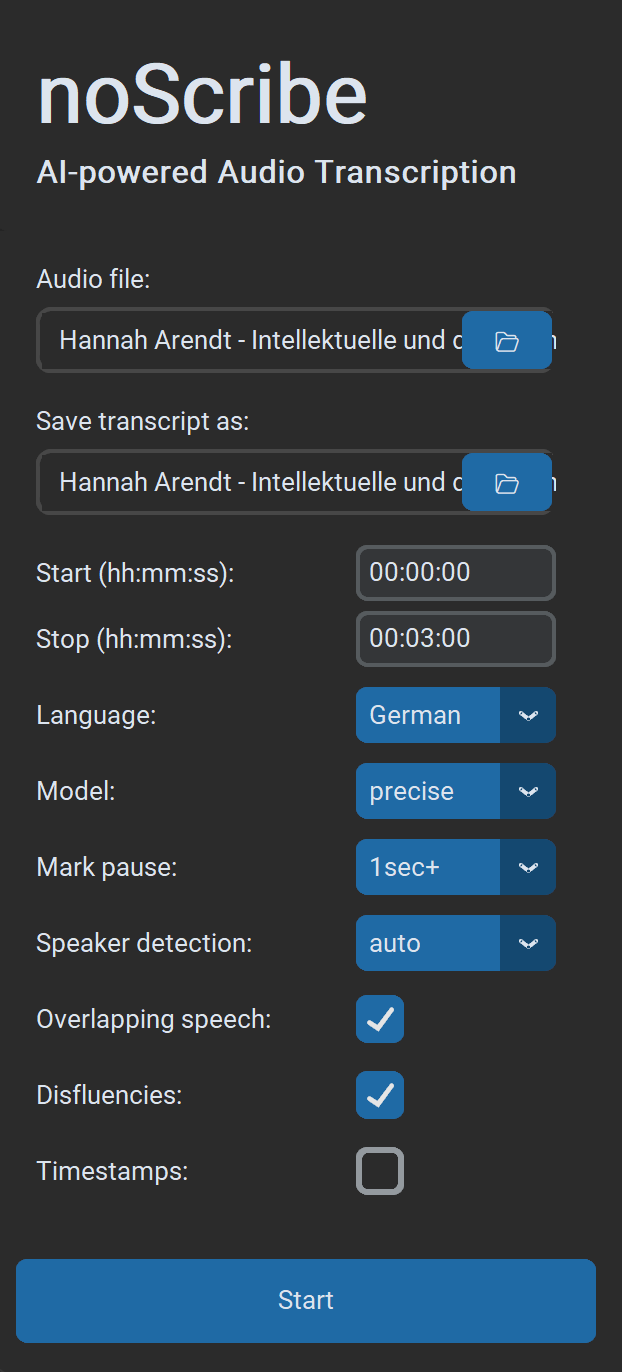
- File audio: Sono supportati quasi tutti i formati audio e video. Puoi anche selezionare più file nella finestra di dialogo; verranno elaborati uno dopo l’altro.
- Salva trascrizione come: Il valore predefinito è
.html(compatibile con l’editor). In alternativa.txtper testo semplice o.vttper sottotitoli e ulteriore lavoro in EXMARaLDA. Se vengono elaborati più file di input alla volta, può essere selezionata solo la cartella di output. I nomi dei file di output vengono generati automaticamente. - Inizio (hh:mm:ss) / Fine (hh:mm:ss): Intervallo di tempo nel formato
hh:mm:ss, ideale per testare estratti più brevi. - Lingua: Seleziona una lingua o “Auto” per il rilevamento, oppure “Multilingual” per più lingue nella stessa registrazione (sperimentale).
- Modello: “Precise” offre i migliori risultati ed è la scelta consigliata per quasi tutti i casi d’uso. “Fast” è un po’ più veloce ed è pensato soprattutto per computer più vecchi. Richiede più correzioni.
- Segna le pause: Se attivato, le pause sono marcate con punti tra parentesi, un punto per ogni secondo di pausa. Opzionale da 1/2/3 secondi.
- Rilevamento degli speaker: Se noto, seleziona il numero di speaker per rendere il rilevamento più robusto. Altrimenti scegli “Auto” per il rilevamento automatico o “None” per saltare del tutto questo passaggio.
- Discorso sovrapposto: Il parlato simultaneo è marcato con
// Speaker: testo dell'interiezione //(sperimentale). - Disfluenze: Se attivato, parole riempitive e parole/frasi incomplete vengono trascritte quando possibile; altrimenti no. Nota: è più una “raccomandazione” al modello di IA, non un interruttore rigido.
- Timestamps: Inserisce un timestamp nel formato
[hh:mm:ss]ogni 60 secondi o ai cambi di speaker (ad esempio, utile per MAXQDA). - Avvia avvia il processo di trascrizione. Se un processo è già in esecuzione, puoi comunque inviarne di nuovi. Questi vengono messi in coda e processati quando arriva il loro turno.
Coda#
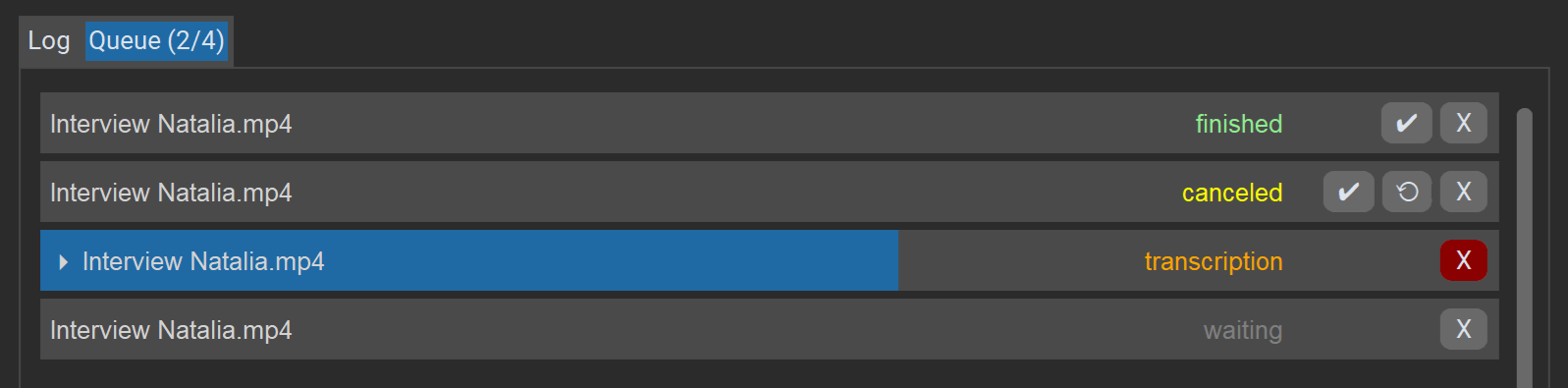
La scheda “Coda” mostra un elenco di tutte le attività della sessione corrente, il loro stato e i progressi. Le attività vengono processate una dopo l’altra.
Azioni per le attività:
Xelimina o annulla l’attività.✔apre il risultato nell’editor (anche se ci sono stati errori, finché esiste una trascrizione incompleta).⟳riavvia un’attività (dopo errori/annullamento).
Il pulsante “Annulla” in basso a destra interrompe l’intera coda.
L’editor noScribe#
L’editor è una parte importante di noScribe. Serve per rivedere e correggere le trascrizioni. Anche con i migliori modelli di IA, questo resta essenziale.
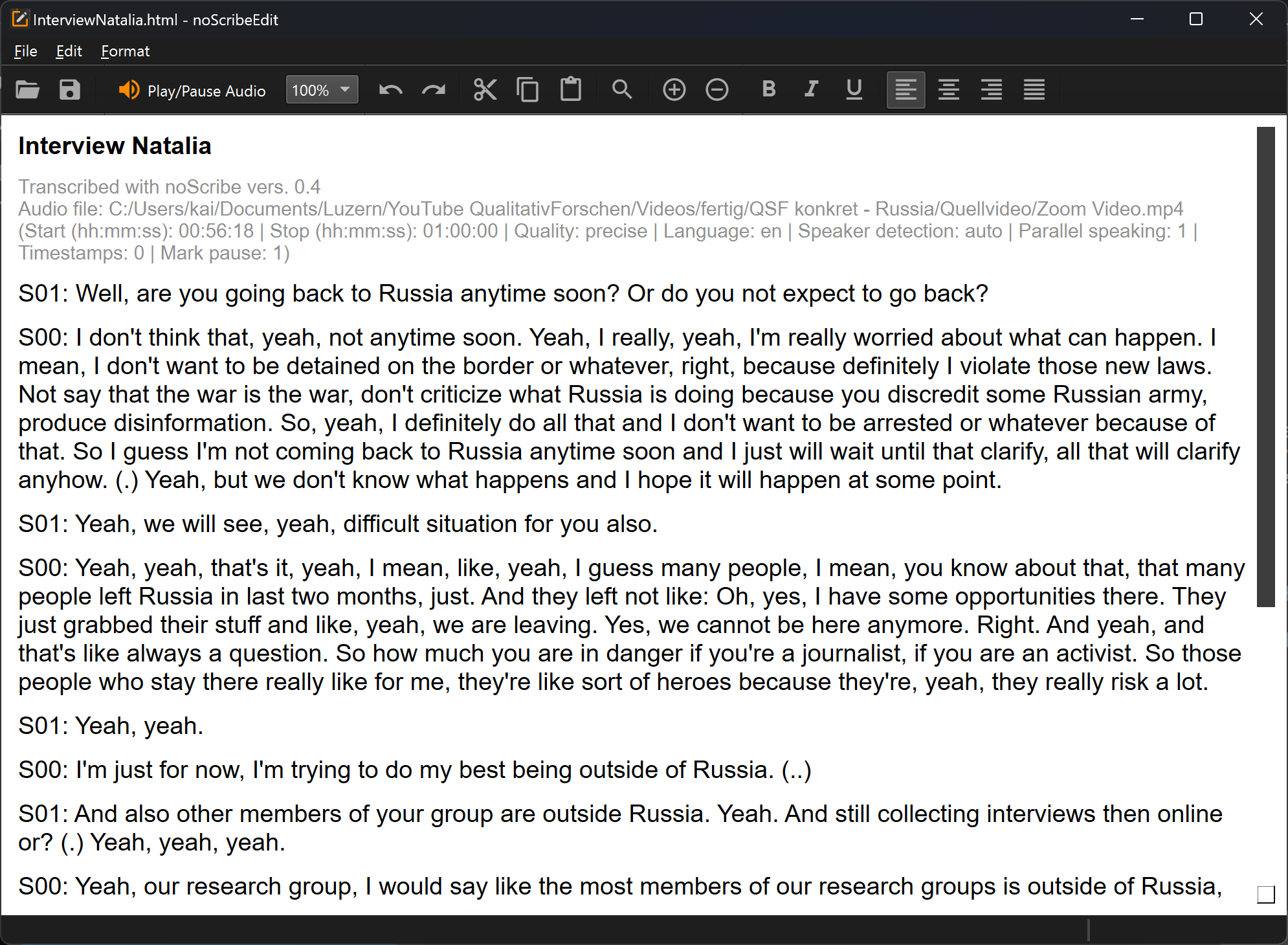
La funzione chiave: Ctrl+Spazio (Mac: ^Spazio) o il pulsante arancione avvia la riproduzione audio nella posizione corrente del cursore. La selezione del testo segue l’audio. Per modificare, fai clic in qualsiasi punto del testo o naviga con i tasti freccia.
Altre funzioni della barra degli strumenti:
- Il menu a tendina (“100%”) permette di aumentare o ridurre la velocità di riproduzione.
- La lente apre una finestra di ricerca/sostituzione. Molto utile, ad esempio, per cambiare i nomi degli speaker.
- Più/Meno: funzione di zoom
- Ci sono anche funzioni tipiche di editor per aprire file, copiare o formattare testo. Le solite scorciatoie da tastiera (ad es. Ctrl+C per copiare) funzionano anche qui. Tutte le funzioni sono accessibili tramite i menu. Purtroppo l’interfaccia dell’editor non e ancora tradotta.
L’editor noScribe è un’app standalone che può essere usata anche indipendentemente dal programma principale.
Codice sorgente: https://github.com/kaixxx/noScribeEditor
Problemi tipici con la trascrizione assistita da IA#
Il riconoscimento vocale assistito da IA ha fatto enormi progressi negli ultimi anni. Tuttavia, ci sono ancora problemi, errori e limiti tipici da considerare:
- Le espressioni non verbali come risate, sospiri, ecc. non vengono catturate e devono essere aggiunte manualmente.
- Il parlato simultaneo e i passaggi molto densi di interazione, ad esempio nelle discussioni di gruppo, sono impegnativi per il modello di IA. Il contenuto può andare perso o essere attribuito alla persona sbagliata.
- A volte vengono rilevati più speaker di quelli effettivamente presenti. In questo caso è utile impostare prima il numero corretto in “Rilevamento degli speaker”.
- Nomi insoliti di persone o organizzazioni, espressioni gergali o parole di altre lingue sono spesso scritti in modo errato, a volte quasi foneticamente. Trova/sostituisci nell’editor noScribe può aiutare.
- Come altri modelli di linguaggio, il modello Whisper utilizzato qui può talvolta “allucinare” e aggiungere parole o frasi che sembrano plausibili ma non sono state dette - vedi questo studio della Cornell University sul tema.
- Raramente possono verificarsi loop di testo che si ripetono all’infinito, simili a un disco difettoso. In questo caso, trascrivi sezioni più brevi con una leggera sovrapposizione e assemblale manualmente.
- Una miscela di più lingue nella stessa registrazione può far sì che il modello di IA traduca invece di trascrivere parola per parola.
- Con file audio lunghi, punteggiatura e maiuscole possono andare perse. In tal caso può aiutare dividere la trascrizione, oppure puoi usare il modello di trascrizione “faster-whisper-large-v2”, meno soggetto a questo problema. Tuttavia, deve prima essere installato.
- La qualità del risultato dipende molto dalla lingua. Le lingue occidentali sono generalmente ben supportate, incluse quelle più piccole come l’olandese. Il supporto è buono anche per coreano, cinese (mandarino) o indonesiano. Al contrario, altre grandi lingue come persiano, punjabi o tamil vengono trascritte con molta meno precisione. Questo è un chiaro caso di bias dell’IA, che riflette gli interessi economici di OpenAI, che ha addestrato il modello Whisper. Ecco una panoramica dei tassi di errore tipici in diverse lingue. Vedi anche questo articolo per un confronto tra modelli di trascrizione e i loro tassi di errore.