Utilisation#
Paramètres#
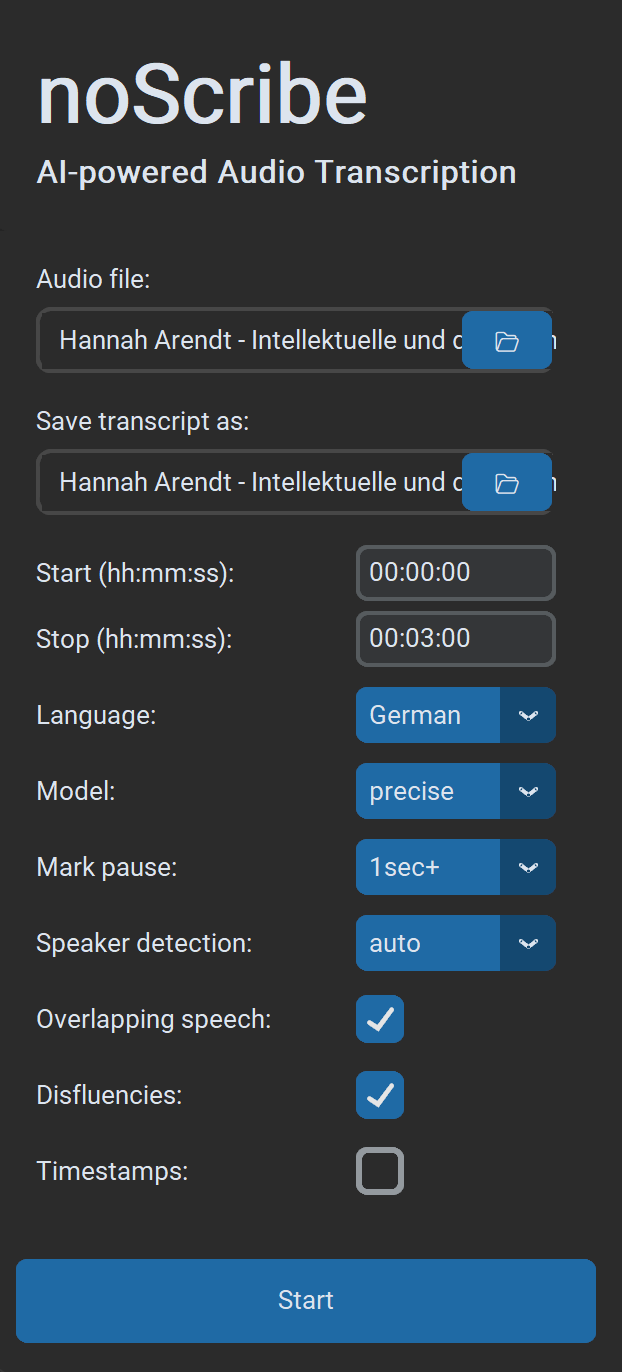
- Fichier audio : Presque tous les formats audio et vidéo sont pris en charge. Vous pouvez aussi sélectionner plusieurs fichiers ; ils seront alors traités les uns après les autres.
- Enregistrer la transcription sous : Par défaut
.html(compatible avec l’éditeur). Optionnellement.txtpour du texte brut ou.vttpour des sous‑titres et un travail ultérieur dans EXMARaLDA. Si plusieurs fichiers d’entrée sont traités d’un coup, seul le dossier de sortie peut être choisi. Les noms de fichiers de sortie sont alors générés automatiquement. - Début (hh:mm:ss) / Fin (hh:mm:ss) : Plage de temps au format
hh:mm:ss, idéale pour tester des extraits plus courts. - Langue : Sélectionnez une langue ou « Auto » pour la détection, ou « Multilingual » pour plusieurs langues dans le même enregistrement (expérimental).
- Modèle : « Precise » donne les meilleurs résultats et est recommandé pour presque tous les usages. « Fast » est un peu plus rapide et est surtout destiné aux ordinateurs plus anciens. Cela nécessite plus de corrections.
- Marquer les pauses : Si activé, les pauses sont marquées par des points entre crochets, un point par seconde de pause. Optionnel à partir de 1/2/3 secondes.
- Détection des locuteurs : Si connue, sélectionnez le nombre de locuteurs pour rendre la détection plus robuste. Sinon choisissez « Auto » pour la détection automatique ou « None » pour ignorer complètement cette étape.
- Chevauchements de parole : La parole simultanée est marquée par
// Locuteur : texte de l’interjection //(expérimental). - Mots de remplissage : Si activé, les mots de remplissage et les mots/phrases incomplètes sont transcrits quand c’est possible ; sinon ils ne le sont pas. Remarque : c’est plutôt une « recommandation » au modèle d’IA, pas un interrupteur strict.
- Horodatage : Insère un horodatage au format
[hh:mm:ss]toutes les 60 secondes ou lors des changements de locuteur (par ex. utile pour MAXQDA). - Démarrer lance le processus de transcription. Si un processus est déjà en cours, vous pouvez tout de même en soumettre de nouveaux. Ils sont alors placés dans la file d’attente et traités à leur tour.
File d’attente#
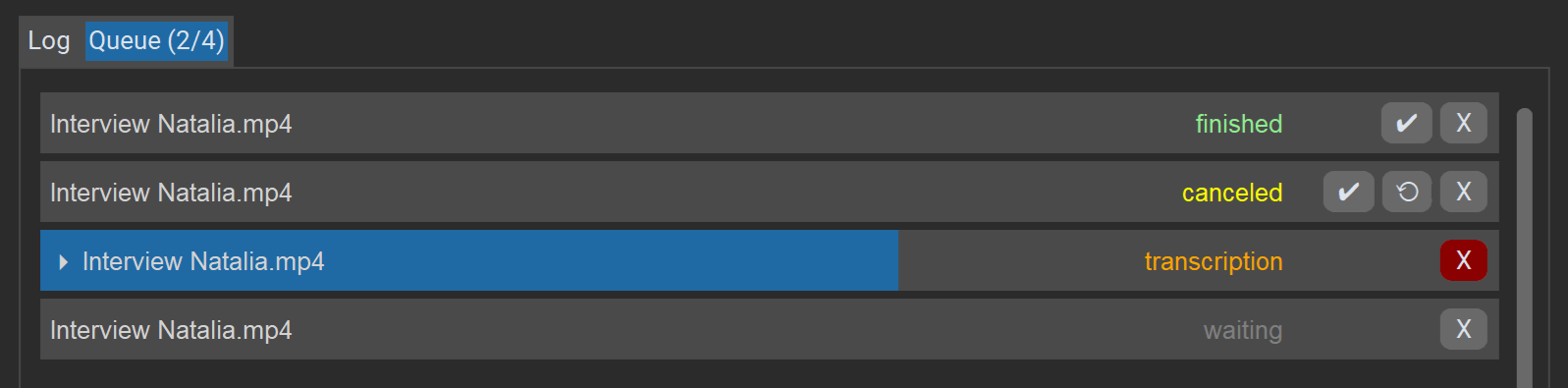
L’onglet « File d’attente » affiche la liste de tous les travaux de la session en cours, leur statut actuel et leur progression. Les travaux sont traités les uns après les autres.
Actions pour les travaux :
Xsupprime ou annule le travail.✔ouvre le résultat dans l’éditeur (même s’il y a eu des erreurs, tant qu’une transcription incomplète existe).⟳redémarre un travail (après erreurs/annulation).
Le bouton « Annuler » en bas à droite arrête toute la file d’attente.
L’éditeur noScribe#
L’éditeur est une partie importante de noScribe. Il sert à relire et corriger les transcriptions. Même avec les meilleurs modèles d’IA, cela reste indispensable.
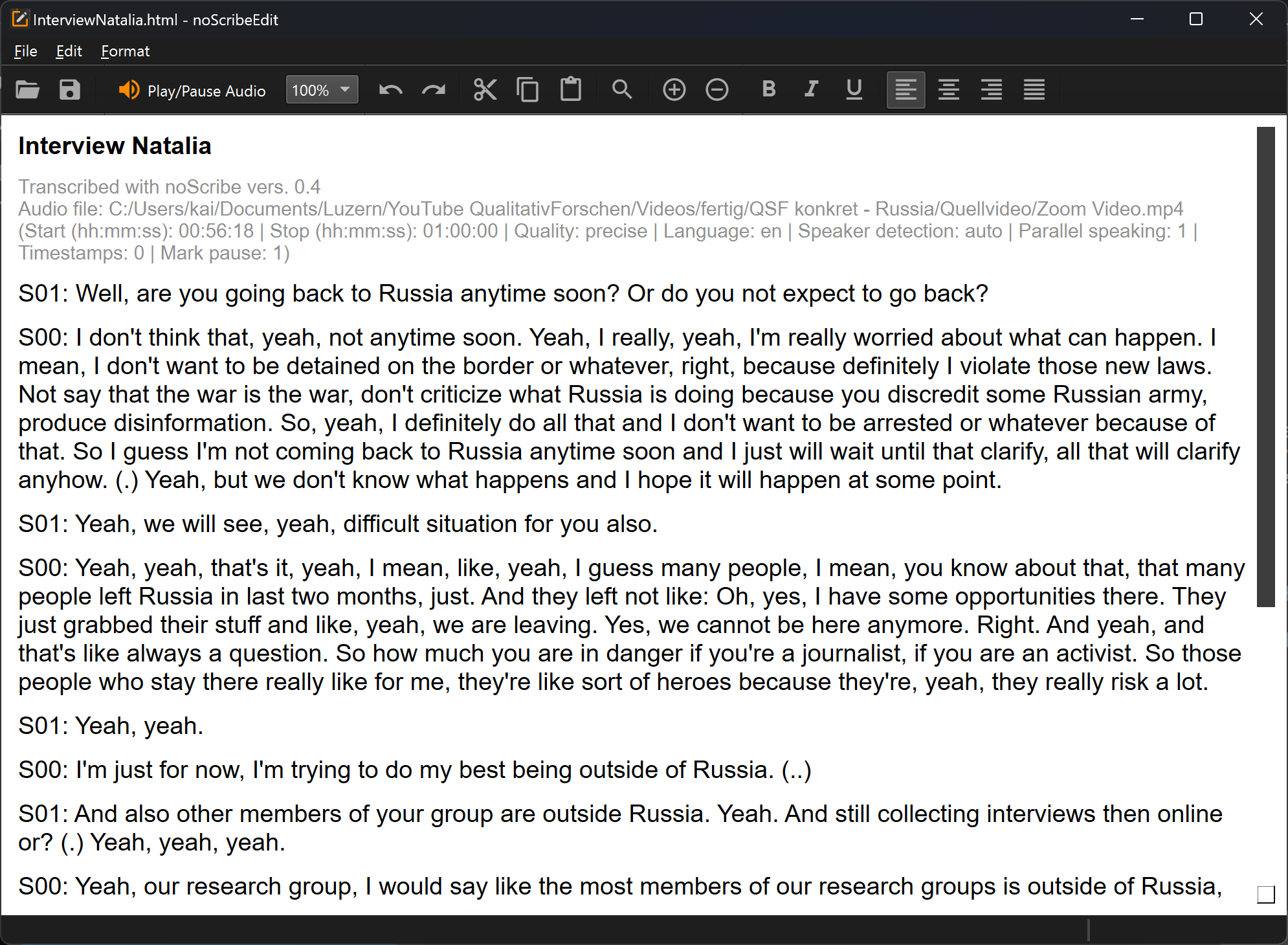
La fonction clé : Ctrl+Espace (Mac : ^Espace) ou le bouton orange démarre la lecture audio à la position du curseur. La sélection de texte suit l’audio. Pour éditer, cliquez simplement n’importe où dans le texte ou naviguez avec les touches fléchées.
Autres fonctions de la barre d’outils :
- La liste déroulante (« 100% ») permet d’augmenter ou de réduire la vitesse de lecture.
- La loupe ouvre une boîte de dialogue de recherche/remplacement. Très utile, par exemple, pour changer les noms des locuteurs.
- Plus/Moins : fonction de zoom
- Il y a aussi des fonctions d’éditeur classiques pour ouvrir des fichiers, copier ou mettre en forme du texte. Les raccourcis habituels (par ex. Ctrl+C pour copier) fonctionnent aussi. Toutes les fonctions sont accessibles via les menus. Malheureusement, l’interface de l’éditeur n’est pas encore traduite.
L’éditeur noScribe est une application autonome qui peut aussi être utilisée indépendamment du programme principal.
Code source : https://github.com/kaixxx/noScribeEditor
Problèmes typiques de transcription assistée par IA#
La reconnaissance vocale assistée par IA a fait d’énormes progrès ces dernières années. Mais il existe encore des problèmes, des erreurs et des limites typiques à surveiller :
- Les expressions non verbales comme les rires, soupirs, etc. ne sont pas capturées et doivent être ajoutées manuellement.
- Les chevauchements de parole et les passages denses d’interaction, par exemple en discussions de groupe, sont difficiles pour le modèle d’IA. Du contenu peut être perdu ou attribué aux mauvaises personnes.
- Parfois, plus de locuteurs sont détectés qu’il n’y en avait réellement. Ici, il est utile de définir le nombre correct dans « Détection des locuteurs » au préalable.
- Les noms inhabituels de personnes ou d’organisations, l’argot, ou des mots d’autres langues sont souvent mal orthographiés, parfois presque phonétiquement. Rechercher/remplacer dans l’éditeur noScribe peut aider.
- Comme d’autres modèles de langage, le modèle Whisper utilisé ici peut parfois « halluciner » et ajouter des mots ou des phrases qui semblent plausibles mais n’ont pas été dits – voir cette étude de l’université Cornell sur le sujet.
- Rarement, des boucles de texte se répétant à l’infini peuvent apparaître, comme un disque défectueux. Dans ce cas, transcrivez des sections plus courtes avec un léger chevauchement et assemblez-les manuellement.
- Un mélange de plusieurs langues dans le même enregistrement peut amener le modèle d’IA à traduire au lieu de transcrire mot à mot.
- Avec de longs fichiers audio, la ponctuation et la capitalisation peuvent être perdues. Dans ce cas, scinder la transcription peut aider, ou vous pouvez utiliser le modèle de transcription « faster-whisper-large-v2 », moins sujet à ce problème. Cependant, il doit d’abord être installé.
- La qualité du résultat dépend fortement de la langue. Les langues occidentales sont généralement très bien prises en charge, y compris des langues plus petites comme le néerlandais. Le support est aussi bon pour le coréen, le chinois (mandarin) ou l’indonésien. En revanche, d’autres grandes langues comme le persan, le pendjabi ou le tamoul sont transcrites bien moins précisément. C’est un cas clair de biais de l’IA, reflétant les intérêts économiques d’OpenAI, qui a entraîné le modèle Whisper. Voici un aperçu des taux d’erreur typiques dans différentes langues. Voir aussi cet article pour une comparaison de différents modèles de transcription et de leurs taux d’erreur.