Uso#
Ajustes#
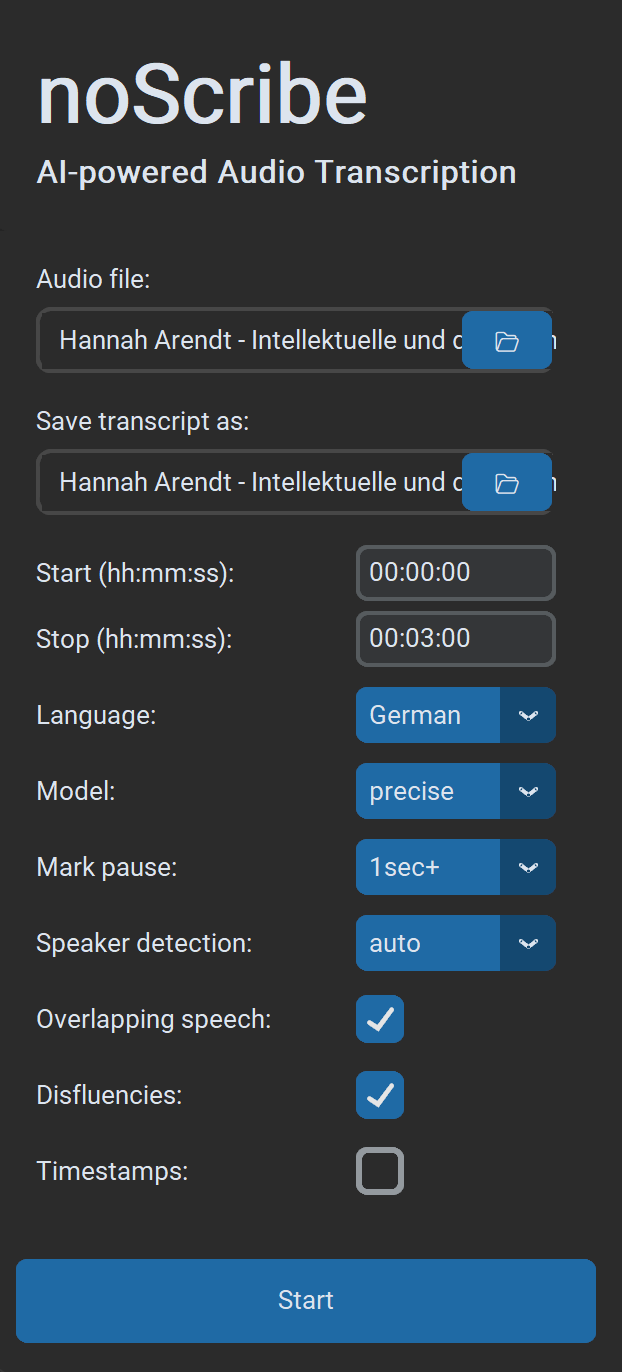
- Archivo de audio: Se admiten casi todos los formatos de audio y vídeo. También puedes seleccionar varios archivos en el diálogo; se procesarán uno tras otro.
- Guardar transcripción como: El valor predeterminado es
.html(compatible con el editor). Opcionalmente.txtpara texto plano o.vttpara subtítulos y trabajo posterior en EXMARaLDA. Si se procesan varios archivos de entrada a la vez, solo se puede seleccionar la carpeta de salida. Los nombres de archivo de salida se generan automáticamente. - Inicio (hh:mm:ss) / Fin (hh:mm:ss): Rango de tiempo en formato
hh:mm:ss, ideal para probar fragmentos más cortos. - Idioma: Selecciona un idioma o «Auto» para detección, o «Multilingual» para varios idiomas en la misma grabación (experimental).
- Modelo: «Precise» ofrece los mejores resultados y es la opción recomendada para casi todos los usos. «Fast» es un poco más rápido y está pensado principalmente para ordenadores más antiguos. Requiere más correcciones.
- Marca pausas: Si está activado, las pausas se marcan con puntos entre corchetes, un punto por segundo de pausa. Opcional desde 1/2/3 segundos.
- Detección de oradores: Si se conoce, selecciona el número de oradores para hacer la detección más robusta. De lo contrario elige «Auto» para detección automática o «None» para omitir este paso por completo.
- Discurso solapado: El habla simultánea se marca con
// Orador: texto de la intervención //(experimental). - Disfluencias: Si está activado, las muletillas y las palabras/frases incompletas se transcriben cuando es posible; si no, no se transcriben. Nota: esto es más bien una «recomendación» al modelo de IA, no un interruptor estricto.
- Timestamps: Inserta un timestamp en formato
[hh:mm:ss]cada 60 segundos o en cambios de orador (por ejemplo, útil para MAXQDA). - Iniciar comienza el proceso de transcripción. Si ya hay un proceso en marcha, igualmente puedes enviar nuevos. Se colocan en la cola y se procesan cuando les toque.
Cola#
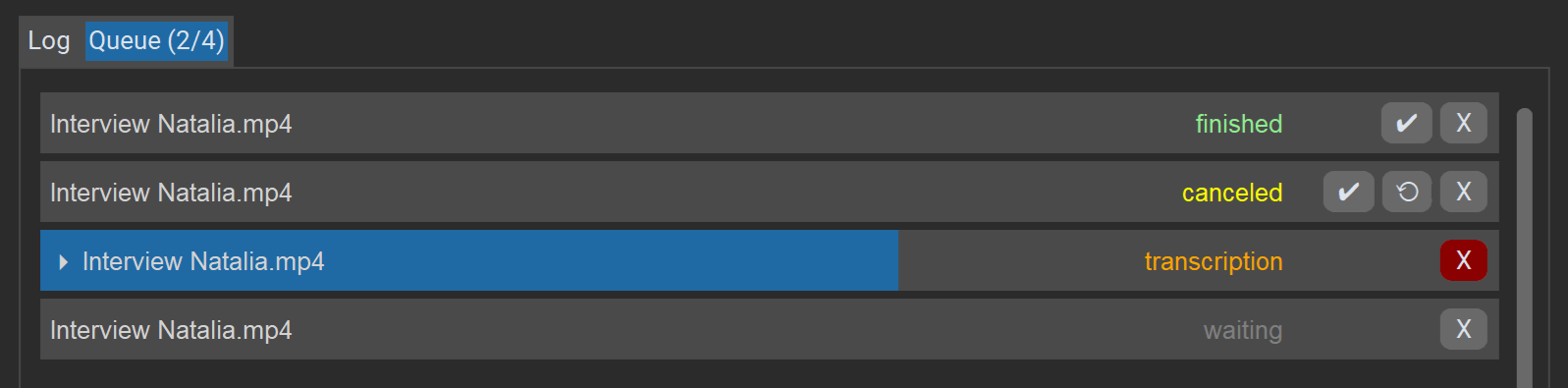
La pestaña «Cola» muestra una lista de todos los trabajos de la sesión actual, su estado y progreso. Los trabajos se procesan uno tras otro.
Acciones para los trabajos:
Xelimina o cancela el trabajo.✔abre el resultado en el editor (incluso si hubo errores, siempre que exista una transcripción incompleta).⟳reinicia un trabajo (tras errores/cancelación).
El botón «Cancelar» en la parte inferior derecha detiene toda la cola.
El editor noScribe#
El editor es una parte importante de noScribe. Se utiliza para revisar y corregir transcripciones. Incluso con los mejores modelos de IA, esto sigue siendo imprescindible.
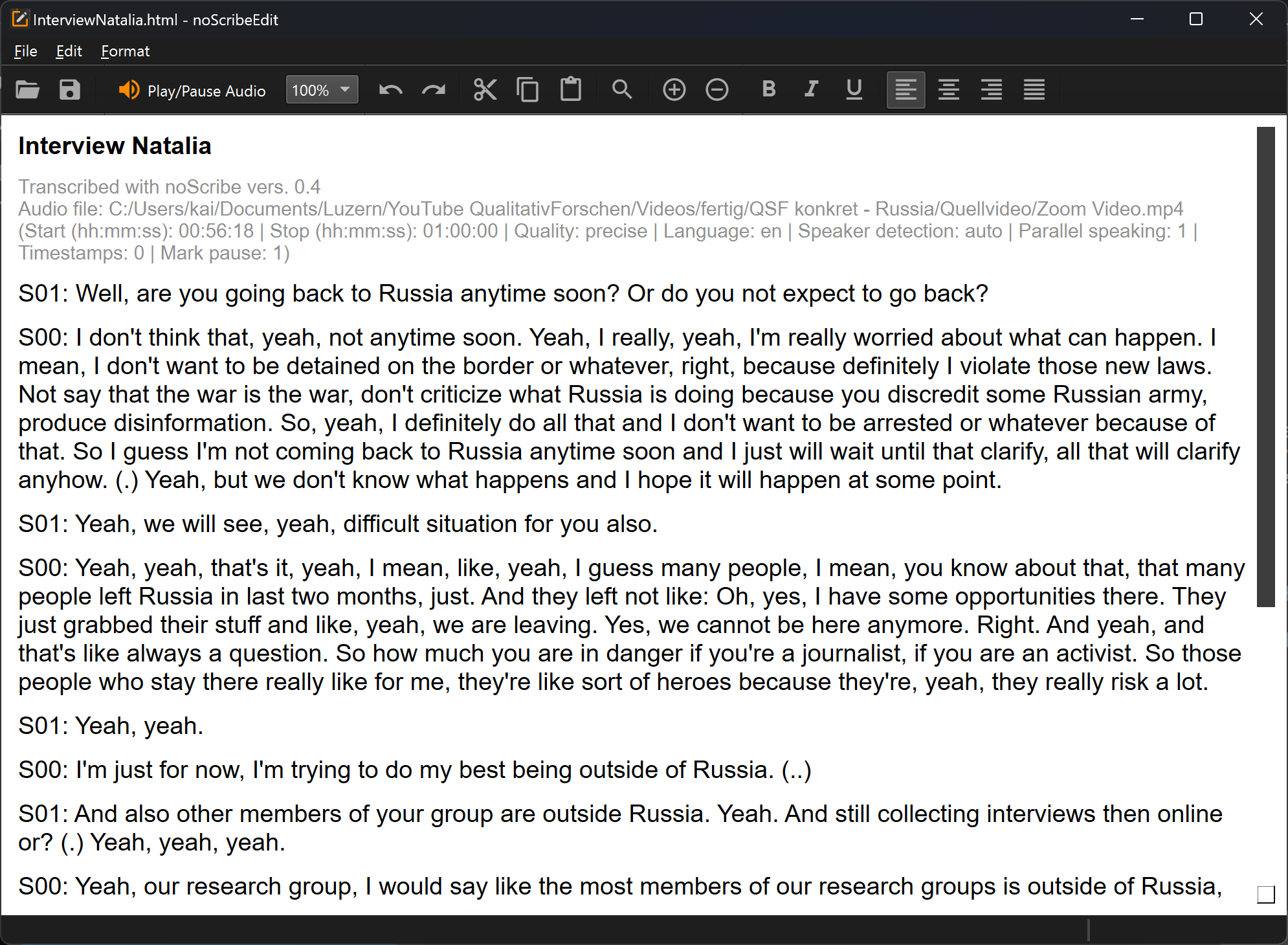
La función clave: Ctrl+Espacio (Mac: ^Espacio) o el botón naranja inicia la reproducción de audio en la posición actual del cursor. La selección de texto sigue el audio. Para editar, haz clic en cualquier parte del texto o navega con las teclas de flecha.
Otras funciones de la barra de herramientas:
- El cuadro combinado («100%») permite aumentar o reducir la velocidad de reproducción.
- La lupa abre un cuadro de búsqueda y reemplazo. Muy útil, por ejemplo, para cambiar nombres de oradores.
- Más/Menos: función de zoom
- También hay funciones típicas de editor para abrir archivos, copiar o dar formato al texto. Los atajos habituales (p. ej., Ctrl+C para copiar) también funcionan. Todas las funciones son accesibles mediante los menús. Lamentablemente, la interfaz del editor aún no está traducida.
El editor noScribe es una aplicación independiente que también puede usarse sin el programa principal.
Código fuente: https://github.com/kaixxx/noScribeEditor
Problemas típicos de la transcripción asistida por IA#
El reconocimiento de voz asistido por IA ha avanzado enormemente en los últimos años. Aun así, hay problemas, errores y limitaciones típicas a tener en cuenta:
- Las expresiones no verbales como risas, suspiros, etc. no se capturan y deben añadirse manualmente.
- El discurso simultáneo y los pasajes de interacción muy densos, por ejemplo en discusiones de grupo, son difíciles para el modelo de IA. Puede perderse contenido o asignarse a personas incorrectas.
- A veces se detectan más oradores de los que realmente había. En ese caso ayuda establecer el número correcto en «Detección de oradores» de antemano.
- Los nombres poco comunes de personas u organizaciones, la jerga o palabras de otros idiomas suelen escribirse mal, a veces casi fonéticamente. Buscar y reemplazar en el editor noScribe puede ayudar.
- Como otros modelos de lenguaje, el modelo Whisper usado aquí a veces puede «alucinar» y añadir palabras o frases que suenan plausibles pero no fueron dichas; consulta este estudio de la Universidad de Cornell sobre el tema.
- En raras ocasiones pueden aparecer bucles de texto que se repiten indefinidamente, parecido a un disco defectuoso. En ese caso, transcribe secciones más cortas con un ligero solapamiento y júntalas manualmente.
- Una mezcla de varios idiomas en la misma grabación puede hacer que el modelo de IA traduzca en lugar de transcribir literalmente.
- Con archivos de audio largos, la puntuación y la capitalización pueden perderse. En ese caso puede ayudar dividir la transcripción, o puedes usar el modelo de transcripción «faster-whisper-large-v2», menos propenso a este problema. Sin embargo, primero debe instalarse.
- La calidad del resultado depende mucho del idioma. Las lenguas occidentales suelen estar muy bien soportadas, incluidas algunas más pequeñas como el neerlandés. También hay buen soporte para coreano, chino (mandarín) o indonesio. En cambio, otras lenguas grandes como el persa, el panyabí o el tamil se transcriben con mucha menos precisión. Esto es un claro caso de sesgo de la IA, que refleja los intereses económicos de OpenAI, que entrenó el modelo Whisper. Aquí tienes un resumen de tasas de error típicas en distintos idiomas. Consulta también este artículo para comparar diferentes modelos de transcripción y sus tasas de error.