Bedienung#
Einstellungen#
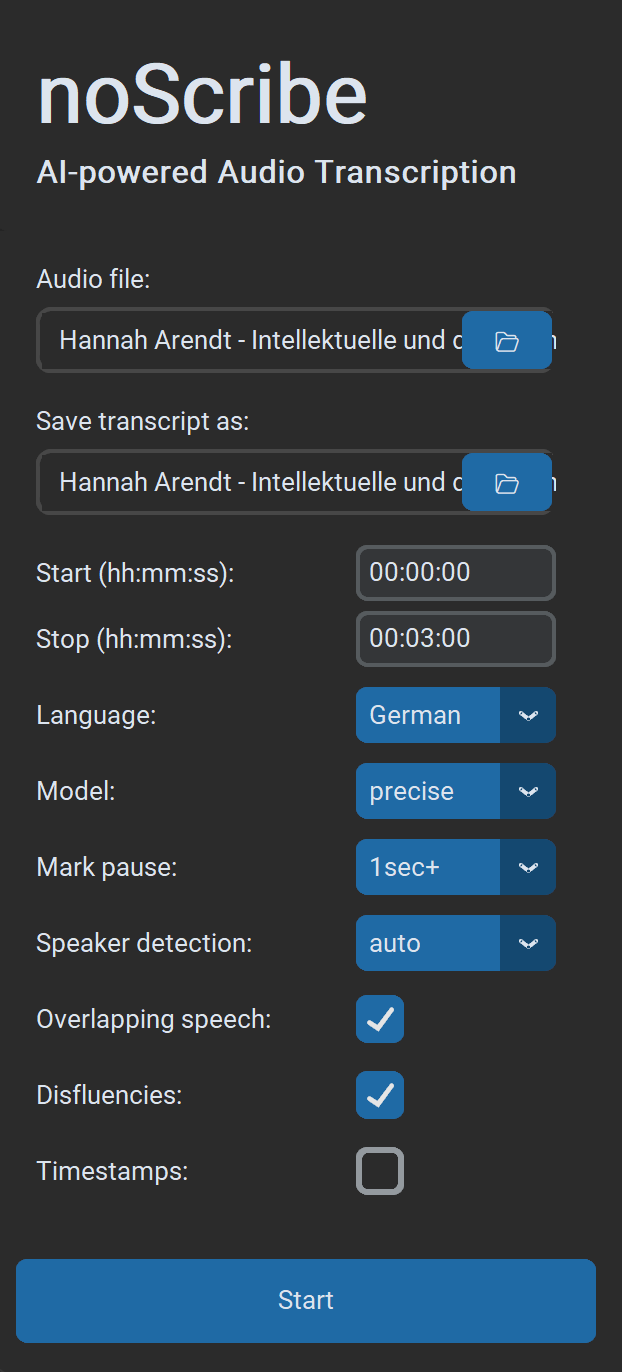
- Audiodatei wählen: Unterstützt werden nahezu alle Audio‑ und Videoformate. Im Dialog können auch mehrere Dateien gewählt werden. Diese werden dann nacheinander abgearbeitet.
- Transkript speichern unter: Standard ist
.html(kompatibel mit dem Editor). Optional.txtfür Klartext oder.vttfür Untertitel sowie die Weiterarbeit in EXMARaLDA. Wenn mehrere Dateien auf einmal verarbeitet werden, kann hier nur der Ausgabeordner gewählt werden. Die Benennung der Ausgabedateien erfolgt dann automatisch. - Start/Stop: Zeitbereich im Format
hh:mm:ss, ideal zum Testen kürzerer Ausschnitte. - Sprache: Sprache auswählen oder „Auto“ zur Erkennung bzw. „Multilingual“ für mehrere Sprachen in derselben Aufnahme (experimentell).
- Qualität: „Precise“ liefert die besten Ergebnisse und ist für fast alle Anwendungszwecke die beste Wahl. „Fast“ ist etwas schneller und vor allem für ältere Rechner gedacht. Es erfordert mehr Nachkorrektur.
- Pausen markieren: Wenn gewählt, werden Sprechpausen als Punkte in Klammern markiert, jeweils ein Punkt pro Sekunde Pause. Optional ab 1/2/3 Sekunden.
- Sprecher:in erkennen: Wenn bekannt, Anzahl der Sprecher:innen wählen, das macht die Erkennung robuster. Ansonsten „Auto“ für die automatische Erkennung oder „None“, um diesen Schritt ganz zu überspringen.
- Überlappende Sprache: Gleichzeitiges Sprechen wird mit
// Sprecher:in: Text des Einwurfs //markiert (experimentell). - Füllworte: Wenn gewählt, werden Füllwörter und unvollständige Worte/Sätze nach Möglichkeit mittranskribiert, sonst nicht. Achtung: Dies ist eher eine ‘Empfehlung’ an das KI-Modell, kein harter Ja/Nein-Schalter.
- Zeitstempel: Fügt einen Zeitstempel im Format
[hh:mm:ss]alle 60 Sekunden oder bei Sprecher:innenwechsel in den Text ein (gut für MAXQDA). - Start beginnt den Transkriptionsprozess. Wenn bereits ein Prozess läuft, können trotzdem neue in Auftrag gegeben werden. Diese werden dann in die Warteschlange eingereiht und erledigt, sobald sie an der Reihe sind.
Warteschlange#
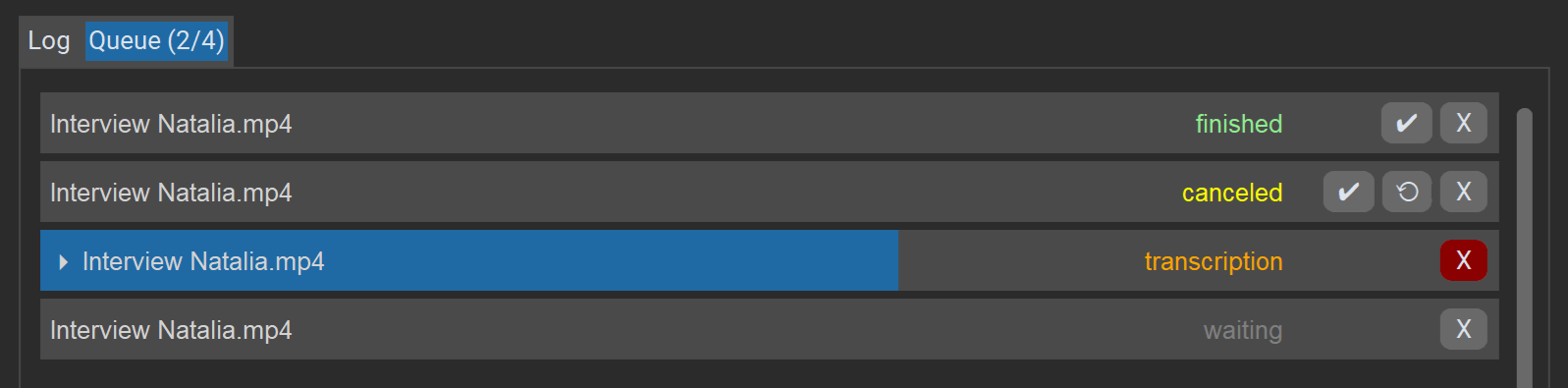
Der Tab „Warteschlange“ zeigt eine Liste aller Aufträge in der aktuellen Sitzung, ihren aktuellen Status und Fortschritt. Die Aufträge werden einer nach dem anderen abgearbeitet.
Aktionen für Aufträge:
Xlöscht oder bricht den Auftrag ab.✔öffnet das Ergebnis im Editor (auch bei Fehlern, sofern ein unvollständiges Transkript vorhanden ist).⟲startet einen Job erneut (bei Fehlern/Abbruch).
Mit dem „Abbrechen“-Button unten rechts kann die gesamte Warteschlange beendet werden.
Der noScribe Editor#
Der Editor ist ein wichtiger Bestandteil von noScribe. Er dient zur Kontrolle und Korrektur der Transkripte. Das ist auch bei den besten KI-Modellen leider immer noch dringend erforderlich.
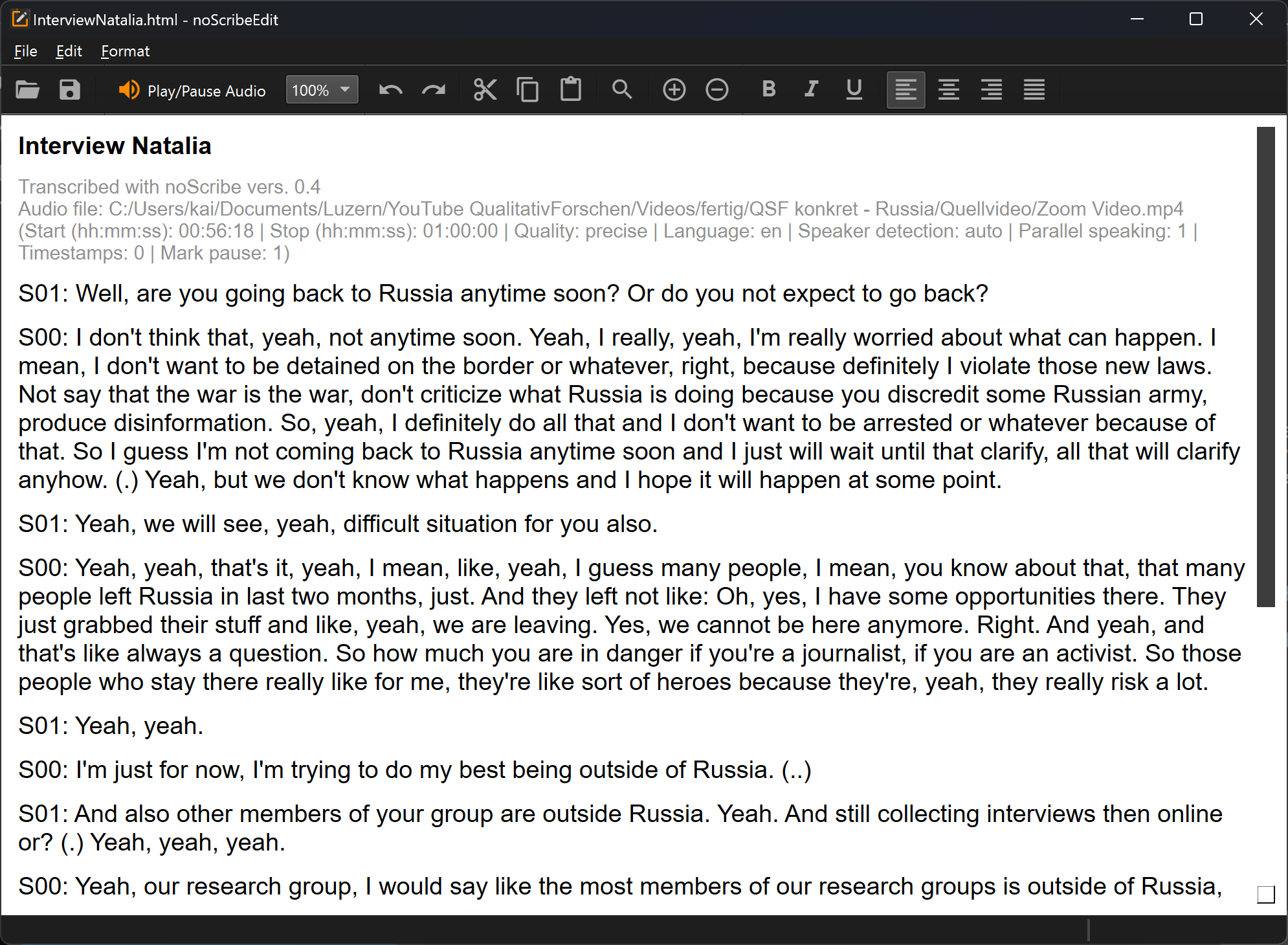
Die wichtigste Funktion: Ctrl+Space (Mac: ^Space) oder der orangene Button starten das Audio an der aktuellen Cursorposition. Die Textauswahl folgt der Audioaufnahme. Zum Editieren einfach an beliebiger Stelle in den Text klicken oder mit den Pfeiltasten navigieren.
Sonstige Funktionen in der Toolbar:
- Im Kombinationsfeld (“100%”) kann man das Abspieltempo erhöhen/reduzieren.
- Mit der Lupe wird ein Suchen/Ersetzen-Dialog aufgerufen. Das ist sehr hilfreich, um beispielsweise die Namen der Sprecher:innen zu ändern.
- Plus/Minus: Zoom‑Funktion
- Außerdem gibt es typische Editor-Funktionen, um Dateien zu öffnen, Text zu kopieren oder zu formatieren. Auch die üblichen Tastenkombinationen (bspw. Strg+C zum Kopieren) funktionieren. Alle Funktionen sind auch über die Menüs erreichbar. Leider ist die Oberfläche des Editors aktuell nicht übersetzt.
Der noScribe Editor ist eine eigenständige App, die auch unabhängig vom Hauptprogramm verwendet werden kann.
Quellcode: https://github.com/kaixxx/noScribeEditor
Typische Probleme KI-gestützter Transkriptionen#
KI-gestützte Spracherkennung hat in den letzten Jahren enorme Fortschritte gemacht. Trotzdem gibt es typische Probleme, Fehler und Einschränkungen, auf die man achten sollte:
- Nonverbale Ausdrücke wie Lachen, Seufzen, etc. werden nicht erfasst und müssen manuell ergänzt werden.
- Gleichzeitiges Sprechen und interaktiv sehr dichte Passagen bspw. in Gruppendiskussionen sind eine Herausforderung für das KI-Modell. Hier gehen auch teils Inhalte verloren oder werden falschen Personen zugeordnet.
- Teils werden mehr Sprecher:innen erkannt, als tatsächlich anwesend waren. Hier hilft es, die korrekte Zahl vorher bei “Sprecher:in erkennen” anzugeben.
- Ungewöhnliche Namen von Personen oder Organisationen, Slangausdrücke oder Wörter aus anderen Sprachen werden oft falsch geschrieben, teils fast lautsprachlich. Hier kann Suchen & Ersetzen im noScribe Editor helfen.
- Wie andere KI-Sprachmodelle kann auch das hier verwendete Modell Whisper manchmal “halluzinieren”, also Worte oder Satzteile hinzufügen, die zwar inhaltlich passend erscheinen, tatsächlich aber nicht gesagt wurden - siehe diese Studie der Cornell University zum Thema.
- Selten können sich fortwährend wiederholende Textschleifen entstehen, ähnlich einer defekten Schallplatte. In diesem Fall kürzere Abschnitte mit leichter Überlappung transkribieren und manuell aneinanderfügen.
- Eine Mischung mehrerer Sprachen in derselben Aufnahme kann dazu führen, dass das KI-Modell übersetzt statt wortgetreu zu transkribieren.
- Bei langen Audios kann die Interpunktion/Kapitalisierung verloren gehen. Auch hier kann eine Aufteilung des Transkripts möglicherweise helfen, oder man verwendet das Transkriptionsmodell “faster-whisper-large-v2”, das weniger anfällig für dieses Problem ist. Es muss allerdings zunächst installiert werden.
- Die Qualität des Ergebnisses hängt stark von der Sprache ab. Westliche Sprachen werden generell sehr gut unterstützt, auch kleinere wie bspw. Niederländisch. Gut ist auch die Unterstützung für Koreanisch, Chinesisch (Mandarin), oder Indonesisch. Dagegen werden andere, ebenfalls große Sprachen wie bspw. Persisch, Panjabi oder Tamil nur sehr fehlerhaft transkribiert. Dies ist ein klarer Fall von KI-Bias, in dem sich die ökonomischen Interessen von OpenAI spiegeln, die das Whisper-Modell trainiert haben. Hier findet man eine Übersicht zu typischen Fehlerraten in verschiedenen Sprachen. Siehe auch dieses Paper für einen Vergleich verschiedener Transkriptionsmodelle und deren Fehlerraten.